Impala在执行的过程中经常遇到OOM的问题,导致我们的有些ETL失败,经常要重跑任务。后面研究发现是我们的配置出现问题了,修改完配置后OOM就再也没有出现过了。
问题
我们的Impala在使用的时候经常会遇到OOM的问题,之前是把Impala和yarn等工具都部署在同一集群中,而且所有工具的内存使用量加起来是大于集群所拥有的实际物理内存的量。所以每次Impala OOM发生的时候,我们都以为是我们的内存不够造成的。但是后面我们把Impala部署到一个单独集群后(有充足的内存),偶尔还是会出OOM的情况。
原因
我们之前的Impala内存配置是这样的:
mem_limit: 70G
Impala Daemon JVM Heap: 60G
我们本来以为这样的配置就相当于,Impala总共使用的内存量是70G,但是实际上Impala可以使用的内存量是130G,如果我们的机器的内存小于130G(我们的内存实际上大概是80G)就会发生OOM。
解决方案
Impala Daemon进程其实是由两个不同的进程组成的。一个进程是用C++写的,它主要用来执行查询语句;另外一个进程是用Java写的,它主要是用来编译执行语句和存储metadata信息。Java的进程被嵌入到C++的进程中,因此他们两个进程共享一个进程号。上述的两个内存参数:mem_limit是用来控制C++进程的内存使用量,而Impala Daemon JVM Heap是用来控制Java进程的内存使用量的。
我们都知道Impala的内存使用量主要都是花费在执行查询的阶段,而存储的metadata的内存量不用太多,所以我们把配置改成如下的方案,就再也没有发生过OOM了。
mem_limit: 70G
Impala Daemon JVM Heap: 10G
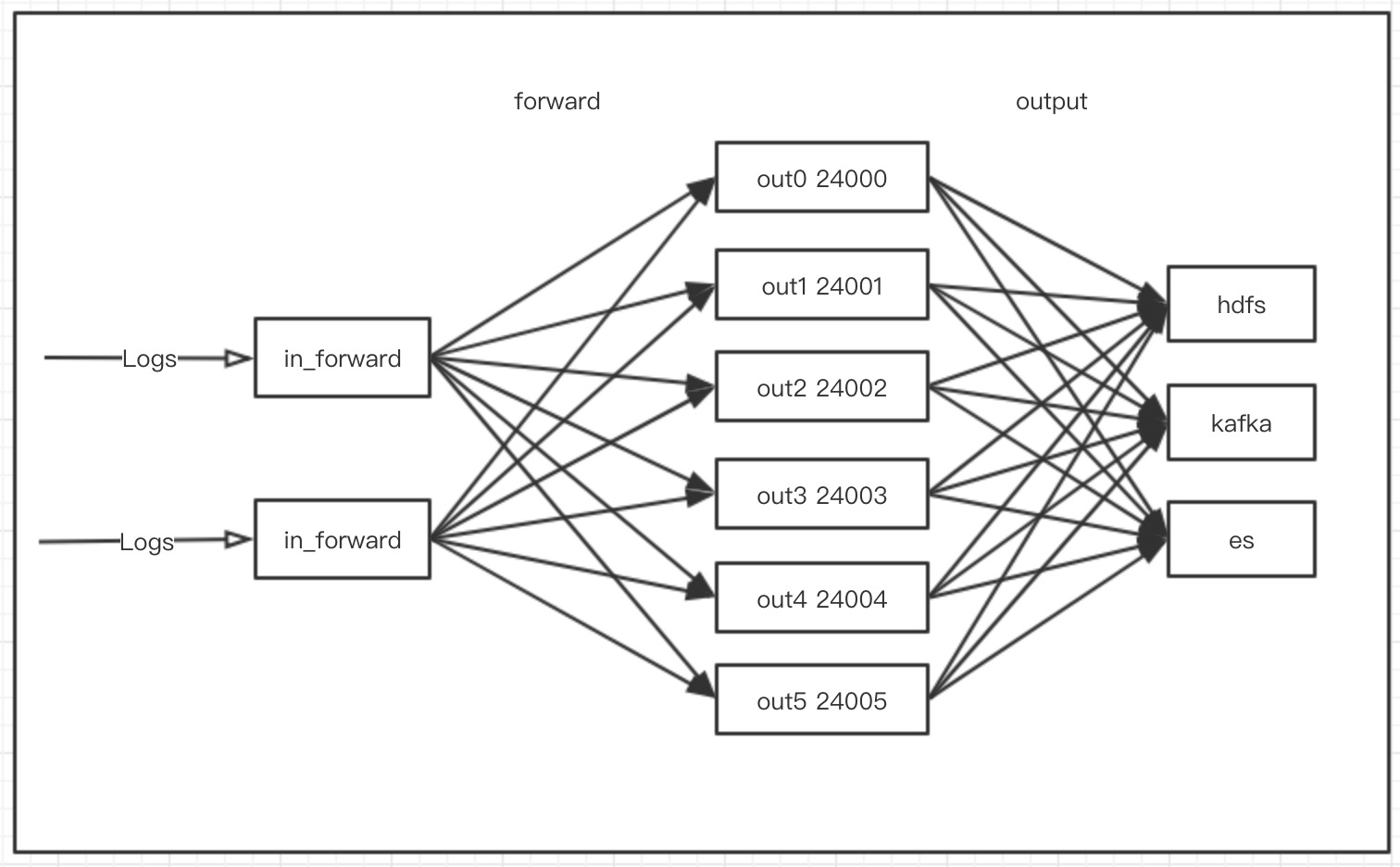 该架构的主要问题是:
该架构的主要问题是: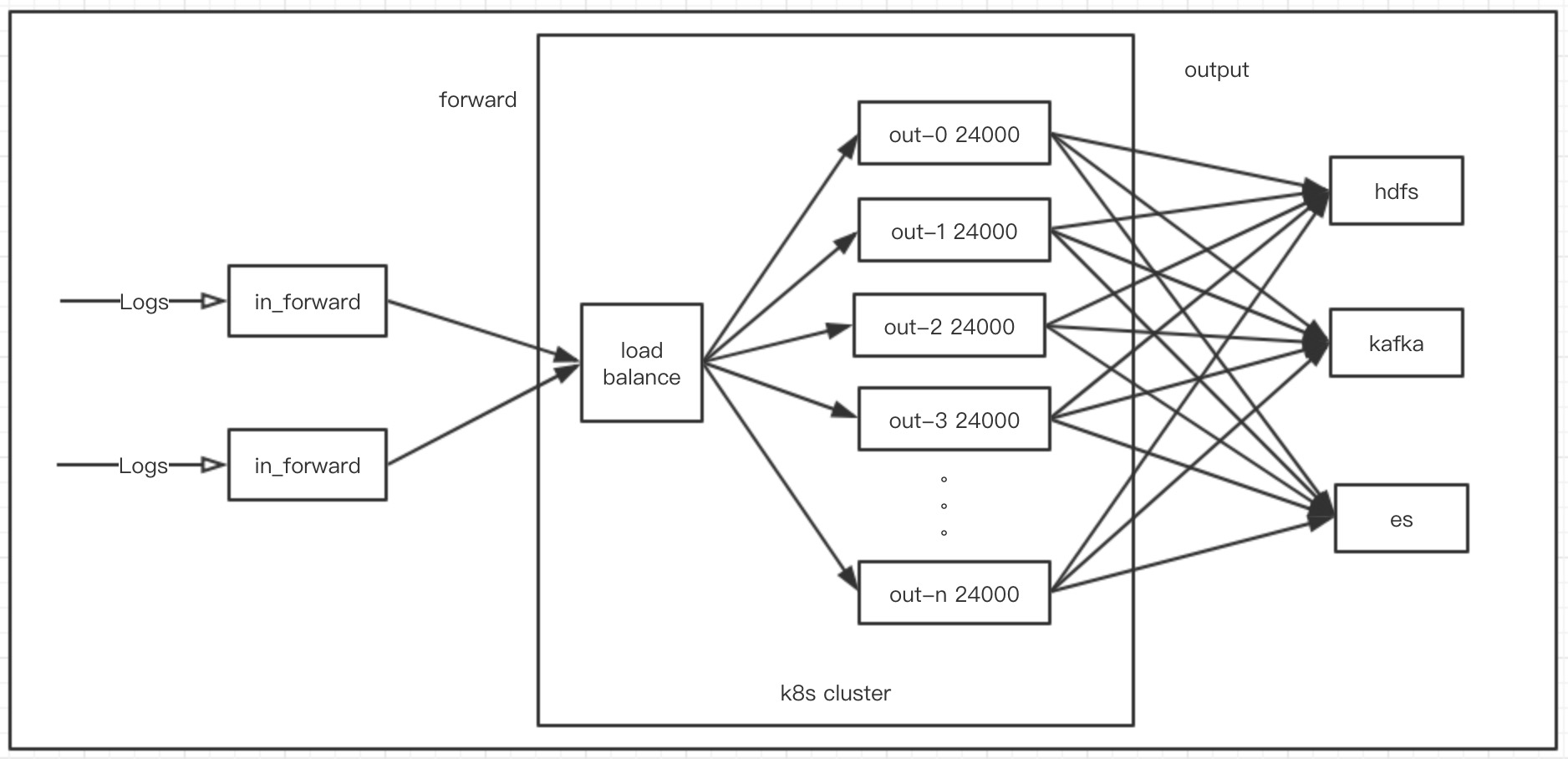 使用该架构后以上的单机问题就没有了,当日志量不断增加的时候,在k8s集群上面我们可以一直增加out进程的数量而不会受到单机性能的限制,甚至我们还可以让fluentd的out进程的数量根据实际的资源使用情况来自动的伸缩。
使用该架构后以上的单机问题就没有了,当日志量不断增加的时候,在k8s集群上面我们可以一直增加out进程的数量而不会受到单机性能的限制,甚至我们还可以让fluentd的out进程的数量根据实际的资源使用情况来自动的伸缩。
 后面查看dnsmasq的man手册知道,dnsmasq的local-ttl参数是控制本地域名的缓存时间的,比如存在
后面查看dnsmasq的man手册知道,dnsmasq的local-ttl参数是控制本地域名的缓存时间的,比如存在