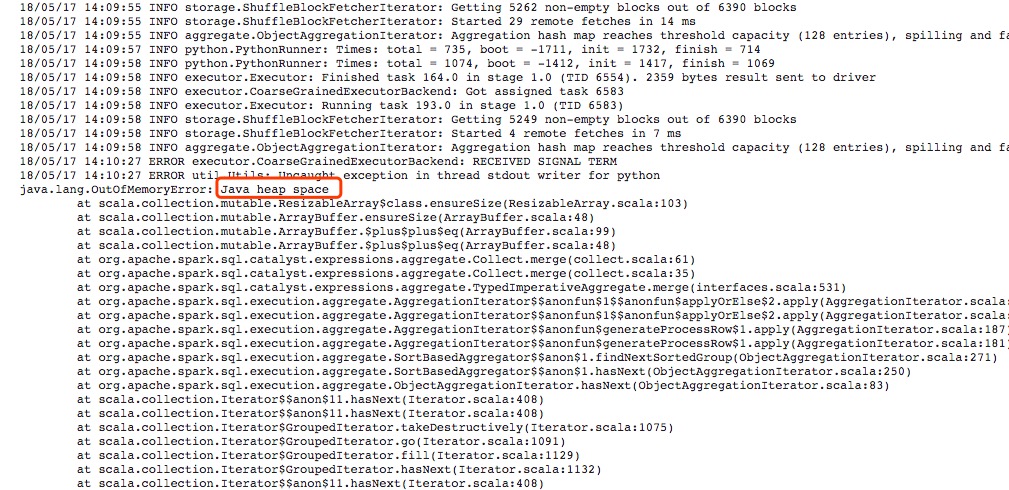
最近在用spark处理数据的时候遇到内存不足的报错,主要的报错信息是在executor端的log中显示java.lang.outofmemoryerror: java heap space。
问题描述
具体的问题是spark在执行到最后一个stage后有一个task一直执行不成功,每次都是重试四次后失败。下面的两张图是具体失败的信息:
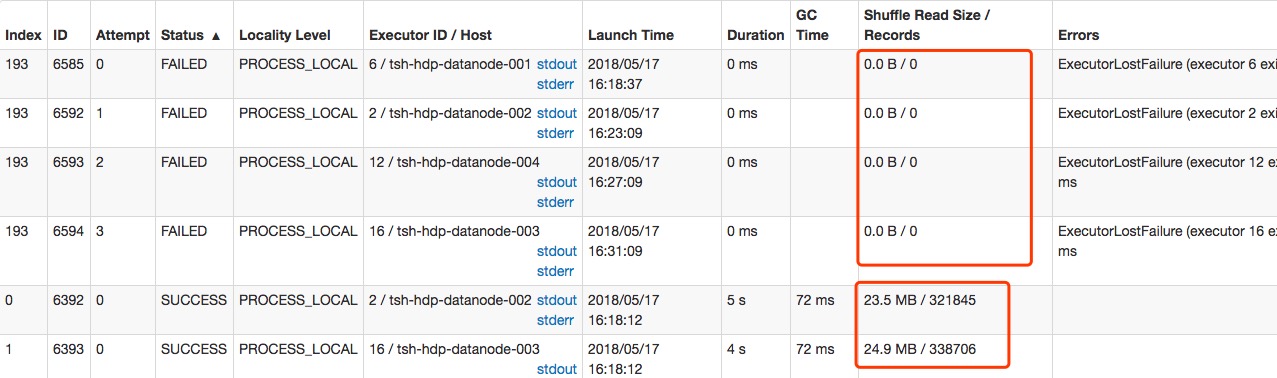
task的失败的信息图中显示:失败的任务的Shffle Read Size是0,这个是不对的,因为这个信息在任务失败的时候都会被置零,实际上在任务在运行的时候这个值是六百多M,远远大于其他task的输入的20多M。
从上面失败的信息中我们可以看到失败的原因是有一个task的输入的数据量太大,以至于spark executor运行的时候需要的内存大大增加,这才导致了内存不足的异常。
问题解决
解决尝试一
最简单直接的解决方法是直接通过增大executor-memory的值来增加executor最大的内存使用量,由于yarn默认的每个executor的core是一个,如果本身启动的executor比较多的话,增加executor-memory的值的话,yarn集群就要多消耗executor的数量✖️增加的内存量的内存,内存的消耗会比较大。所以可以减少executor的数量,为每个executor分配多个core,这样需要的内存量就大大的减少了,但是每个executor可以使用的内存量又可以增加,这样的配置可以减少因为数据倾斜导致任务失败的概率。
最终我们用这个方法把每个executor的executor-memory值增大到了12G,但是最后还是由于内存不够失败了。
解决尝试二
由于某个task需要的内存量非常的大,然而其他task的内存量都很小,这应该不是简单的数据倾斜。spark sql只是对玩家的登陆数据进行以device_id为key的group by操作,数据的倾斜不可能这么严重。
在重新观察了玩家的登陆数据后,我发现有很多数据的device_id为null。这下就很清楚的知道数据倾斜的原因了,接着对device_id为null的数据进行过滤后,问题就迎刃而解了。
总结
在处理数据倾斜问题的时候可以通过调整spark的参数来优化任务的执行。但是如果想更彻底的优化任务的执行的话,要观察数据,知道是什么原因造成的数据倾斜。这样才能进行更彻底的优化。

