最近做了一些离线的etl,因为用到了kudu,所以大部分的etl都是在impala下面执行的。下面的性能优化是我在使用impala的时候总结的一些经验。
COMPUTE STATS
impala在做join的时候会根据表格的实际情况采用更优化的join方案,但是如果impala不知道表的统计信息(比如表格的大小)的话就不能定制优化的join方案,而compute stats命令就是用来让impala产生表的统计信息的命令。正常的情况下把所有要执行的表都执行下compute stats就能有最好的性能,但是有时候impala的优化也不一定是最好的,所以我们必须懂得自己分析执行的过程。
EXPLAIN
在执行sql语句之前可以使用explain命令来查看impala计划执行该sql的流程和预估消耗的资源。要优化sql语句的话最方便的就是改完sql语句后直接执行explain命令,因为该命令不用执行sql语句,可以很方便的调优sql语句,而不用任何的等待。在hue的执行窗口有explain的命令可以直接按,非常的方便。
SUMMARY
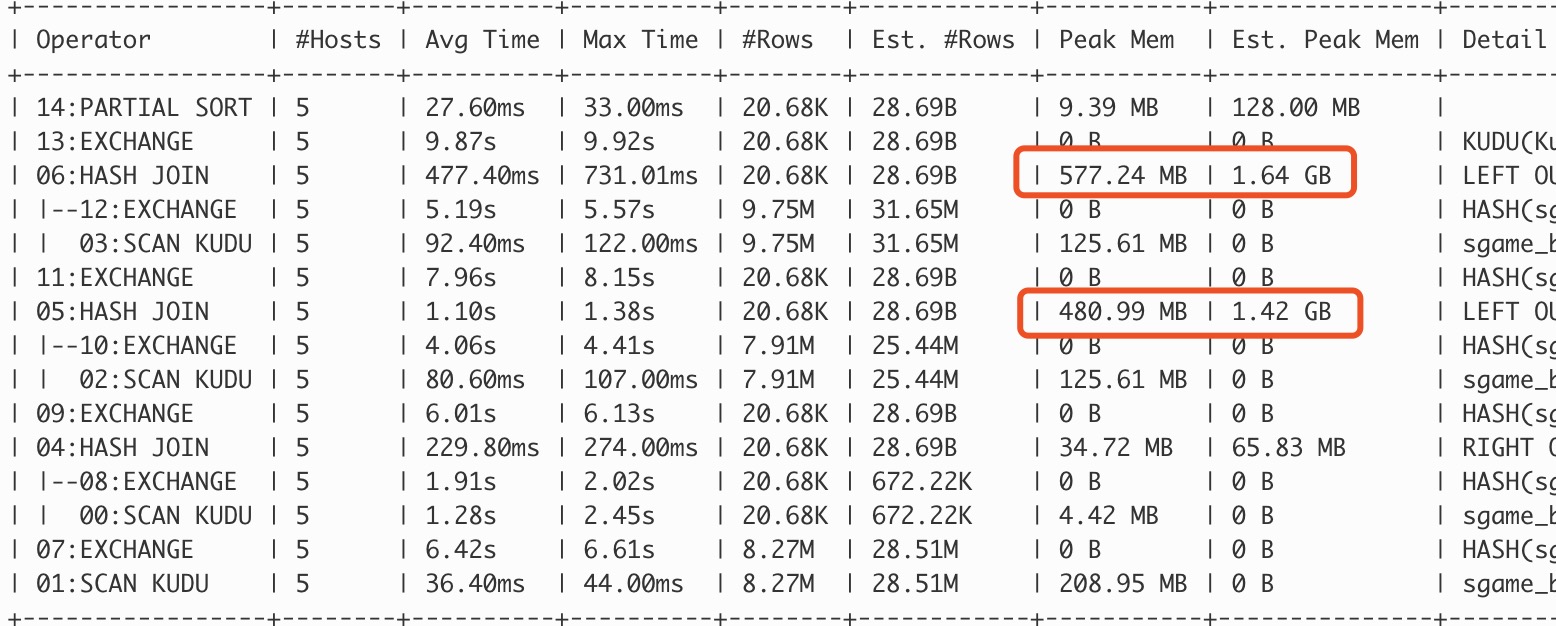
explain命令虽然在大多数的情况下是能够预估sql语句的执行情况,但是毕竟没有执行sql语句,所以预估的情况可能和实际情况会有一些出入。所以这时候我们可以使用summary,在一条语句执行完以后立马执行summary命令就能看到这条sql语句执行时所消耗的时间和资源的情况,还有impala预估的资源使用,有时候预估和实际情况还是有很多不同的。如下图所示的summary的预估内存和实际使用的内存就要较大的出入。当然如果想要看到更详细的执行信息还可以用Profiles命令,但是由于我在优化的过程中没有使用到,这边就不多说了。
SQL语句提示信息
通过上面的explain和summary后我们就能清楚的知道我们的sql语句的性能瓶颈在哪里,但是有时候即使执行了compute stats命令,impala还是不能优化这些性能瓶颈的问题,也就是说,impala的优化不能保证是最优的。所以我们就要告诉impala按照我们自己的想法来执行sql语句。比如:使用STRAIGHT_JOIN命令就可以告诉impala按照我写的sql语句的join顺序来执行join过程,而不进行重排(因为有时候重排的效果更差)。在join后使用-- +SHUFFLE注释就可以告诉impala使用SHUFFLE的方式进行join,而不是BROADCAST的方式进行join。我之前优化的一个sql语句因为加了-- +SHUFFLE注释而减少了好几G的内存使用量。
总结
这篇文章只是粗略的介绍下可以优化的点,具体的优化过程还是得结合自己的sql语句来定制自己的优化方案,如果想了解更多的优化技巧请移步impala官网的文档。

