我们的日志收集系统使用的是Fluentd,使用Fluentd的原因大概是因为配置简单、插件比较多、而且能够比较容易的定制自己的插件。但是随着日志越来越多以后,Fluentd会出现性能上的问题,以下的文章将回顾我们进行Fluentd性能优化的操作。
Fluentd 性能问题的主要原因?
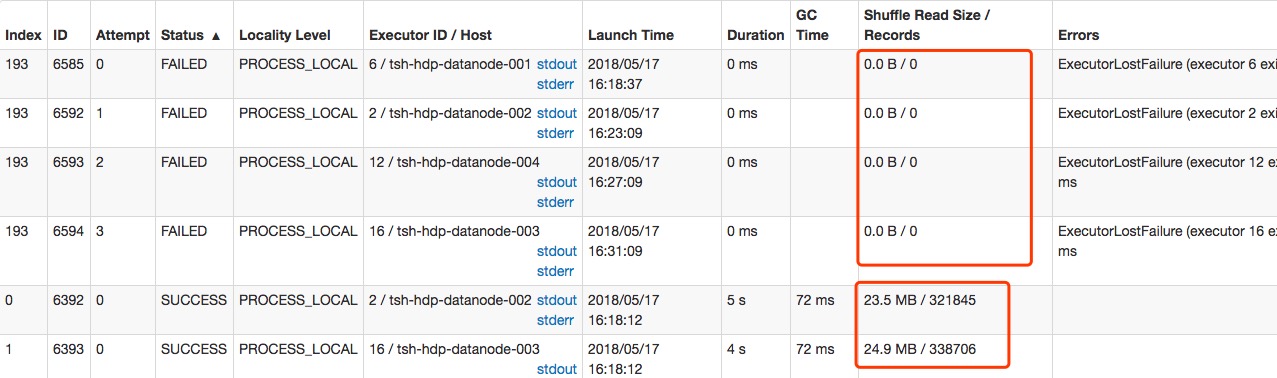
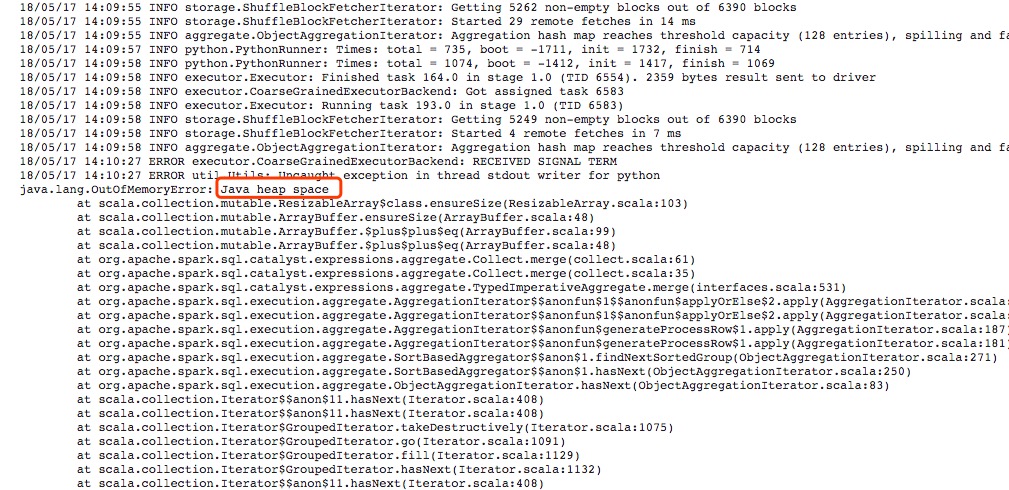
抛开自己配置错误的一些原因,Fluentd性能问题的最主要原因是因为Fluentd是使用Ruby写的,而Ruby有全局锁(GIL),因而在一个Ruby进程里面同时最多只有一个线程在运行。这样的话,Ruby的多线程对需要更多计算资源的操作显得无能为力,具体的体现可以用top查看进程的运行情况,如果Fluentd到达性能瓶颈的话,Fluentd的进程会一直占用100%左右的计算资源,再也不能提升,对于有四个核的计算机来说,最多也就使用的1/4的计算能力,这是极其浪费的。而且当Fluentd进程到达瓶颈后,数据会处理不完,导致数据收集的速度落后于数据产生的速度。
Fluentd 多进程优化一
既然已经知道了Fluentd性能瓶颈的问题主要是因为单进程不能使用多核的计算能力,那解决的方法也是很简单的,可以把收集的日志按照不同的类型来拆分成不同的进程,这样就能充分的利用多核的计算能力了。
多进程架构
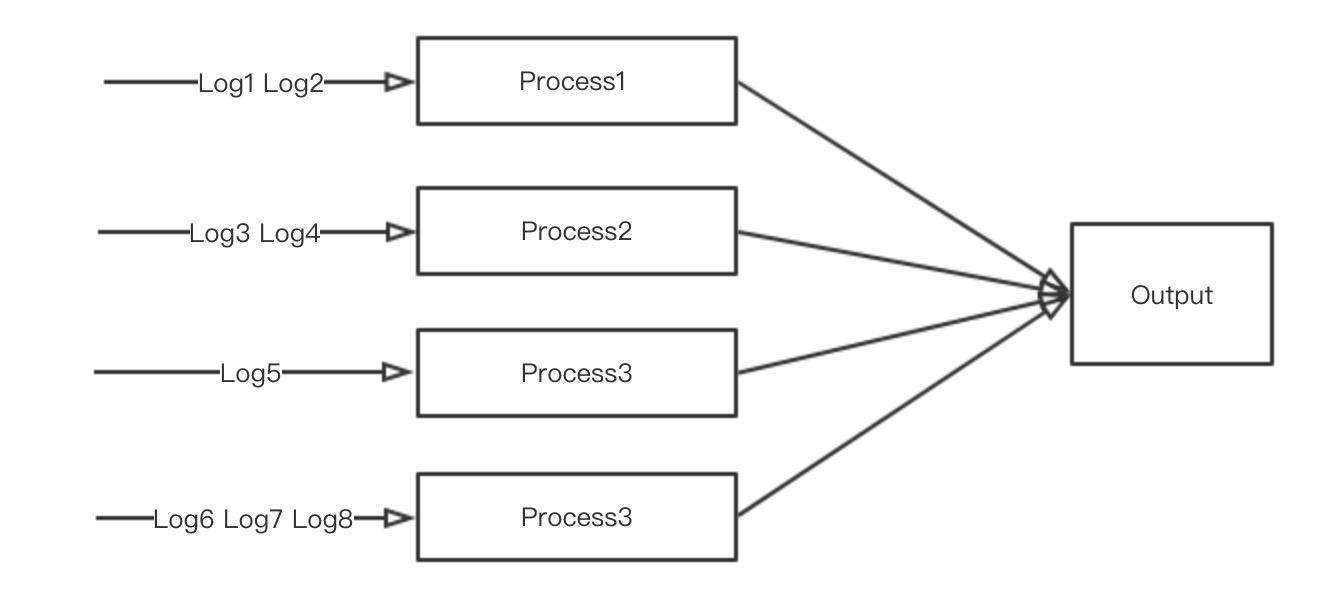 如上图所示,之前单进程的架构可以改成如上的多进程架构,这样每个进程最多可以使用100%的cpu资源,理论上四核的机器起四个Fluentd进程就可以充分的利用机器的计算资源的了,但是实际上这个架构还有一些问题未能解决。
如上图所示,之前单进程的架构可以改成如上的多进程架构,这样每个进程最多可以使用100%的cpu资源,理论上四核的机器起四个Fluentd进程就可以充分的利用机器的计算资源的了,但是实际上这个架构还有一些问题未能解决。
主要问题
这个多进程的架构相比于单进程的架构在性能上已经有很大的提升了,不过还有如下两个问题:
- 该架构要求Log的拆分要比较均衡,这样每个进程都能合理的利用计算资源,不然会出现有些进程非常繁忙,但是有些进程却非常的空闲。然而Log的拆分是按照之前的经验来拆分的,不可能做到绝对的均衡,而且拆分完后是直接写到配置文件里面的,也不能进行实时调整。
- 即使是按照现在的架构进行日志拆分了,但是有些日志的计算任务比较繁重,有可能导致即使一个进程只处理一个类型的Log也会到达性能瓶颈。如上图的Process3只处理Log5,但是在top中却看到Process3的cpu使用率一直是100%,这说明Process3已经到达了性能瓶颈,但是Log5已经不能再进行拆分了。
基于上面的这两个问题,这种多进程架构还是会遇到性能瓶颈,因此需要对架构再继续进行优化,接下来介绍新的架构来优化Fluentd的性能。
Fluentd 多进程优化二
上面的日志拆分架构其实在我们的系统中已经用过了一段时间了,但是我们发现有些Fluentd进程一直很繁忙,我们本来是想着怎么把日志拆分的更加均衡一些,但是无意中在Fluentd官网中看到了他们推荐的架构,觉得这才是真正正确的做法,之前走的是弯路。
新的多进程架构
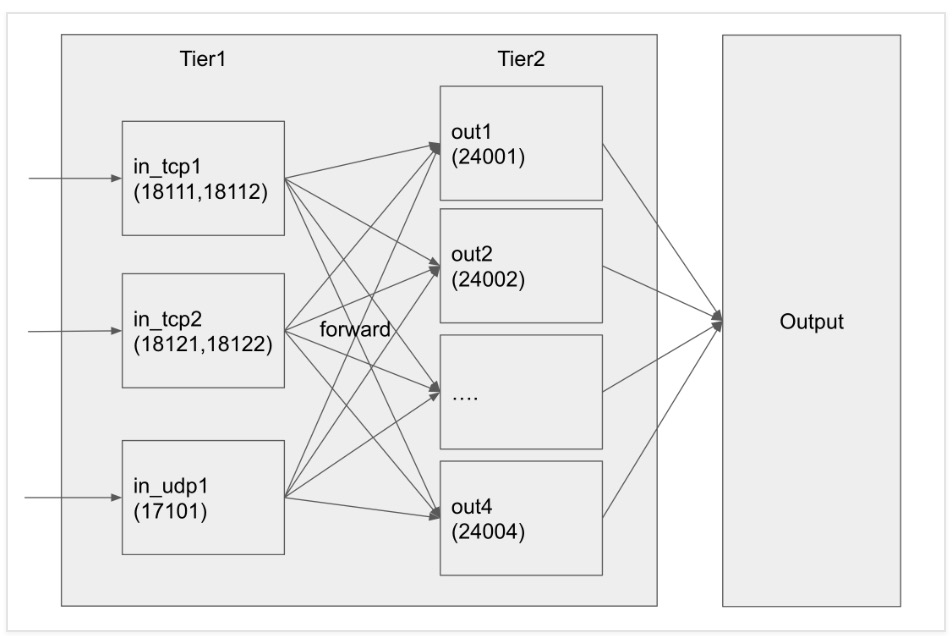 这是Fluentd官网给出的多进程架构图,该架构采用两层的结构,前面的一层只负责数据的路由,把数据按照一定的比例路由到第二层,然后第二层才对数据进行处理。第二层可以根据机器的资源起不同个数的进程,甚至可以把第二层部署到不同的机器上去。这样就能解决旧的架构的分配不均和计算瓶颈的问题了,每种日志都能很均衡的使用机器的计算资源,甚至可以分布式扩展。同时也不用苦恼于怎么拆分Log来让进程的计算资源更加的均衡。
这是Fluentd官网给出的多进程架构图,该架构采用两层的结构,前面的一层只负责数据的路由,把数据按照一定的比例路由到第二层,然后第二层才对数据进行处理。第二层可以根据机器的资源起不同个数的进程,甚至可以把第二层部署到不同的机器上去。这样就能解决旧的架构的分配不均和计算瓶颈的问题了,每种日志都能很均衡的使用机器的计算资源,甚至可以分布式扩展。同时也不用苦恼于怎么拆分Log来让进程的计算资源更加的均衡。
注意事项
新的架构虽然在理论上是非常好的架构,但是在配置的过程中需要注意一些问题:
- 新架构第一层使用的是forward插件把log路由到第二层的,需要注意的是forward的插件也是需要把buffer_type配置成文件的,不然如果第二层的处理能力不够的话,就会导致第一层的buffer数据一直堆在内存里面,导致内存不够。还会造成在停Fluentd进程的时候,如果是第二层进程先停的话,那么第一层的数据会不能发送的到第二层,第一层的进程会一直停不掉。如果机器不小心关掉的话,还会造成数据丢失。
- 新架构第一层的flush_interval(推荐1秒)和buffer_chunk_size(推荐1M)要配置的尽量小,这样数据才能尽快的发送到第二层进行处理。其实如果配置的比较大的话,到时候第二层会有报警的。
- 新架构的缺点是同一种Log会有多个处理进程,这样的话就会导致一些只能单进程处理的操作变得不那么优美了。比如webhdfs插件,现在使用新的多进程架构后,因为每个hdfs文件只能由一个进程写入,所以现在同一种Log是由多个进程写入的,只能写入到多个不同的文件,这样会造成hdfs文件数量成倍的增加。
配置实例
下面给出了一个比较简单的配置实例,该实例只适用于单机版本。如果数据比较多的话,还可以把out_fluent.x.conf的配置文件扩展到多台机器。
multiprocess.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<source>
@type monitor_agent
bind 0.0.0.0
port 24220
</source>
<source>
@type multiprocess
<process>
cmdline -c in_fluentd.conf --log logs/in_fluentd.conf.log
sleep_before_start 1s
sleep_before_shutdown 5s
</process>
<process>
cmdline -c out_fluent.0.conf --log logs/out_fluent.0.conf.log
sleep_before_start 1s
sleep_before_shutdown 5s
</process>
<process>
cmdline -c out_fluent.1.conf --log logs/out_fluent.1.conf.log
sleep_before_start 1s
sleep_before_shutdown 5s
</process>
</source>
in_fluentd.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32<source>
@type tail
@log_level warn
format tsv
keys source,version,event_time
time_key event_time
time_format %Y-%m-%d %H:%M:%S
path /data/*/rolelogout.*
pos_file logs/fluentd/pos/rolelogout.pos
refresh_interval 10s
read_from_head true
keep_time_key true
tag pro_role_logout
</source>
<match pro_role_logout>
@type forward
num_threads 4
buffer_type file
buffer_queue_limit 2048
buffer_chunk_limit 10m
flush_interval 10s
buffer_path logs/fluentd/buffer/in_pro_role_logout.buffer
<server>
host 127.0.0.1
port 24000
</server>
<server>
host 127.0.0.1
port 24001
</server>
</match>
out_fluent.0.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30<source>
@type forward
port 24000
bind 0.0.0.0
</source>
<match pro_role_logout>
@type forest
subtype webhdfs
<template>
username webuser
namenode tsh-hdp-namenode-001:50070
standby_namenode tsh-hdp-namenode-002:50070
path /raw_logs/dt=%Y-%m-%d/role_logout.${tag}.%Y%m%d%H.VPROFLTDSG.0.log
flush_interval 10s
field_separator TAB
buffer_queue_limit 1024
buffer_chunk_limit 16m
buffer_type file
buffer_path logs/fluentd/buffer/webhdfs_role_logout.${tag}.VPROFLTDSG.0.buffer
output_include_time false
output_include_tag false
output_data_type attr:version,event_time
flush_at_shutdown true
retry_wait 30s
num_threads 1
read_timeout 180
open_timeout 120
</template>
</match>
out_fluent.1.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30<source>
@type forward
port 24001
bind 0.0.0.0
</source>
<match pro_role_logout>
@type forest
subtype webhdfs
<template>
username webuser
namenode tsh-hdp-namenode-001:50070
standby_namenode tsh-hdp-namenode-002:50070
path /raw_logs/dt=%Y-%m-%d/rrole_logout.${tag}.%Y%m%d%H.VPROFLTDSG.1.log
flush_interval 10s
field_separator TAB
buffer_queue_limit 1024
buffer_chunk_limit 16m
buffer_type file
buffer_path logs/fluentd/buffer/webhdfs_role_logout.${tag}.VPROFLTDSG.0.buffer
output_include_time false
output_include_tag false
output_data_type attr:version,event_time
flush_at_shutdown true
retry_wait 30s
num_threads 1
read_timeout 180
open_timeout 120
</template>
</match>
总结
通过这次架构的升级,Fluentd的性能已经得到了很大的提升,而且配置也变得更加简单了,好的架构往往能够事半功倍。