由于Erlang的官方文档并没有介绍垃圾回收机制,本文参考一些论文和博客试着来解释下Erlang的内存回收机制,如果有存在错误,欢迎指正。
要解释Erlang的垃圾回收机制必须先知道Erlang的内存管理,在Erlang中存在三种架构来实现不同的内存管理方式,在之前的很长一段时间内用的都是process-centric的架构,现在不知道有没有改成Hybrid,没有找到相关的说明文档。接下来分别介绍下这三种架构:
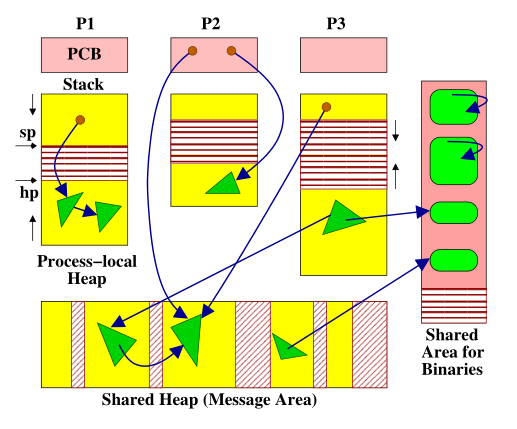
- Process-centric 在该架构中,进程间通信需要复制消息,因此是O(n)操作,其中n是消息大小。内存碎片通常比较多。预计垃圾回收的时间和次数预计会很小(因为根集只需要堆叠的进程需要收集),并且在进程终止之后,其分配的内存区域可以在不间断的时间内被回收。在图1中相当于没有Shared Heap区域。
- Communal 这种架构的最大的优点是非常快(O(1))的通信,只需将指针传递给接收进程,由于消息共享,所以内存的需求也比较小,并且分散性低。缺点在于,必须将所有进程的堆栈作为根集的一部分(导致增加GC延迟),并且由于进程的数据在共享堆上交错而导致可能的缓存性能差。此外,这种架构不能很好地扩展到多线程或多处理器实现,因为需要锁定以便以并行设置分配和收集共享存储器区域。简单的说所有的消息都是共享的,进程内只存了指针。
- Hybrid 这是一种尝试结合上述两个架构的优点的架构:进程间通信可能很快,并且进程本地堆的频繁收集的GC延迟预计会很小。对进程本地堆的垃圾收集不需要锁定,并且减少了共享堆上的压力,因此它不需要经常进行垃圾回收。而且,像Process-centric架构一样,当一个进程终止时,它的本地内存可以通过简单地将其附加到自由列表(free-list)来回收。图1是该架构的内存组织图。
由于之前Erlang里面默认采用的是Process-centric的架构,所以我们这边介绍Process-centric架构的内存回收方式,如果想要了解Hybrid的内存回收方式可以参考《Message Analysis-Guided Allocation and Low-Pause》这篇论文。
Process-centric架构由于没有Shared Heap,所以内存回收只涉及到进程的内存回收和Shared Area for Binaries的内存回收。
进程内存回收
如图1所示,Erlang的进程和Linux的进程非常的像,由进程控制块(PCB)、堆(Stack)和栈(Heap)组成。
- 进程控制块:进程控制模块会保存一些关于进程的信息比如它在进程表中的标识符(PID)、当前状态(运行、等待)、它的注册名、初始和当前调用,同时PCB也会保存一些指向传入消息的指针,这些传入消息是存储在堆中连接表中的。
- 栈:它是一个向下增长的存储区,这个存储区保存输入和输出参数、返回地址、本地变量和用于执行表达式的临时空间。
- 堆:它是一个向上增长的存储区,这个存储区保存进程邮箱的物理消息,像列表、元组和Binaries这种的复合项以及比像浮点数这种一个机器字更大的对象。超过64机器字的二进制项不会存储在进程私有堆里,而是被存在图1的Shared Area for Binaries里面,进程堆维护一个列表(remembered list),该列表存储该进程指向Shared Area for Binaries区域的所有指针。
进程的内存回收机制采用的是分代标记清除(“stop the world” generational mark-sweep collector)的回收机制,通过这种机制把进程堆划分为了一个老年代(Old Generation)和新生代(Young Generation),使用minor collection对新生代进行垃圾回收,major collection进行整个堆的垃圾回收。进程垃圾回收的时候该进程会卡住,但是由于进程堆的大小一般都比较小所以回收的很快,而且这时候其他进程也在运行,所以垃圾回收不太会影响系统的响应能力。进程创建后的首次垃圾回收会使用major collection,后面在进程运行的过程中如果发现内存不够用的话会先使用minor collection进行回收,如果还是不能释放出足够的空间的话则会使用major collection进行回收,然后如果major collection还是不能释放出足够的空间的话,则会增加进程堆的大小。进程默认的min_heap_size的大小是233个字,进程堆大小的增长策略首先是斐波纳契序列增长,当堆的大小到达1.3M个字的时候堆每次只增长20%。
Shared Area for Binaries内存回收
这个区域的内存回收采用的是标记清除的方法,在每个Binary的头部上会有一个数字,记录着这个Binary被引用了几次。在进程结束之后,进程堆中的remembered list的指针指向的Binary的引用次数会被相应的减1,同样在进程垃圾回收的时候如果发现remembered list中有可以被回收的指针,该指针所指向的Binary的引用次数也会被相应的减1,当一个Bianry的引用次数为0时,这个Binary就可以被回收。
建议
通过了解Erlang垃圾回收的原理,可以在垃圾回收方面对系统进行一些调优,以及减少系统的内存使用量,以下是我总结的一些建议:
- 进程默认的min_heap_size的大小是233个字,如果能提前知道进程大概需要多少空间的话,在进程创建的时候指定min_heap_size的大小可以减少内存回收的次数。
由于进程内存回收是每个进程单独进行的,所以有些进程在申请了很多空间之后,很久没有运行,但是上次申请的空间其实有些已经没用了,如果进程一直不运行或者不触发回收,这部分内存就一直回收不了,这时候就需要手动的进行内存回收。建议可以定时执行以下代码进行内存回收:
1
2[erlang:garbage_collect(P) || P <- erlang:processes(),
{status, waiting} =:= erlang:process_info(P, status)],我所在的项目在每次启动的时候都会进行大量的初始化,在项目启动成功后对所有进程一次手动回收也可以节省很多内存。
- 对一些重量级的操作可以spawn一个进程出来处理,当进程结束后该部分空间就能被完全回收了,比在原进程上面执行应该会好些。
- 之前看到一个开源项目在处理完一个请求后就对该进程进行一次手动回收,这个好像也是一个优化,因为一个请求过后再上来一个请求的话,可能需要秒的级别,进程在这段空闲时间进行一次回收不会影响系统的响应而且还能节省内存。